All
为什么要持久化数据
由于Redis是在内存中进行存储的,当机器重启后内存里面的数据就会丢失。我们不希望这些数据是临时数据,希望它能在重启之后仍然存在,或者我们能将数据导出在其他机器上直接进行导入。这时候都需要进行持久化,将数据落盘。
持久化的方式
持久化的方式在Redis 4.x版本后有了一些区别!
持久化方式主要有两种:
- RDB
- AOF
题目描述
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
示例 1:
输入:arr = [3,2,1], k = 2 输出:[1,2] 或者 [2,1] 示例 2:
输入:arr = [0,1,2,1], k = 1 输出:[0]
限制:
0 <= k <= arr.length <= 10000 0 <=
arr[i]<= 10000
给定一个数组,找出最小的k个数,对这k个数的大小顺序没有要求。
解题思路
这个题目我最开始的想法是用堆来解决的,但我解答完成看题解的时候发现了一种做法:
排序后取前k个元素
在评论区中有很多人在讨论这一种解法,虽然的他复杂度比较高,实现方式很简单,有一些专业人士在鄙视这种做法,也有一些人说这个题目的难度是简单,所以用这个也没什么问题。我的看法是支持这种做法,并不因为他的难度级别,而是解决问题的思路。在解决问题的时候每一种思路都是可取的。
什么是堆
堆是一种特殊的树,它满足以下两点:
-
堆是一个完全二叉树
完全二叉树要求,除最后一层,其他层的节点个数都是满的,最后一次的节点都靠左排列。
-
堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值
当前节点的值是子树中的最大或最小值。
我们将每个节点的值都大于等于子树中每个节点值的堆,叫做“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫做“小顶堆”
我们来看一下例子:
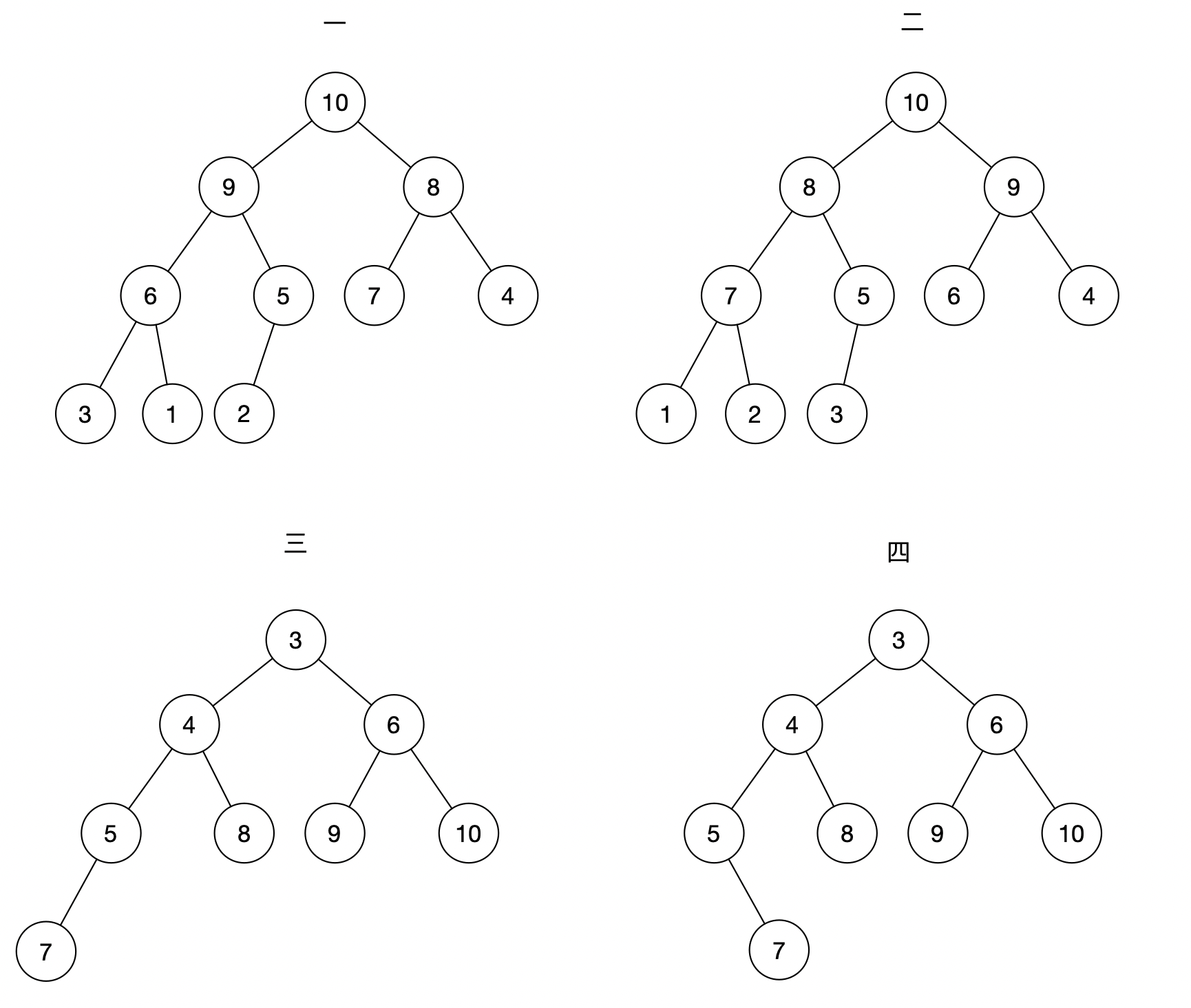
在上面的四个实例中,我们根据以上两条规则,可以判断出:
第一个、第二个是大顶堆,第三个是小顶堆,第四个由于不是完全二叉树所以不是堆。
fail-fast与fail-safe
在Collection集合的各个类中,有线程安全和线程不安全这2大类的版本。
对于线程不安全的类,并发情况下可能会出现fail-fast情况;而线程安全的类,可能出现fail-safe的情况。
**快速失败(fail—fast)**是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
**安全失败(fail-safe)**保存了该集合对象的一个快照副本。你可以并发读取,不会抛出异常,但是不保证你遍历读取的值和当前集合对象的状态是一致的!
fail-fast
来看一下线程不安全的类ArrayList,它实现fail-fast主要靠一个字段modCount。来从头认识一下它。
首先找到引用它的地方:
|
|
可以看出,在增加元素,删除元素时都会对modCount值加一。当我们查看更新,查找的代码时并没有找到对modCount的修改。
modCount字段翻译过来就是修改次数,再结合上面的代码可以了解到只有在结构发生变化,数量增减的时候才会修改。查找不会对结构发生变化也不用修改,至于更新操作,虽然它修改了值,但是在结构上总体的数量没有改变,结构上指的是:是谁不重要,有就行。
题目描述
给定一个二叉树,返回其节点值的锯齿形层次遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
例如: 给定二叉树 [3,9,20,null,null,15,7],
3 / \ 9 20 / \ 15 7返回锯齿形层次遍历如下:
\[ \[3], \[20,9], \[15,7] ]
所谓的锯齿形遍历,即是在第一层从左向右遍历,在第二层从右向左遍历,依次遍历完成。
题目描述
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例 1:
输入: [3,2,3] 输出: 3 示例 2:
输入: [2,2,1,1,1,2,2] 输出: 2
题目描述
给你 n 个非负整数 a1,a2,…,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
说明:你不能倾斜容器,且 n 的值至少为 2。
图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
示例:
输入:[1,8,6,2,5,4,8,3,7] 输出:49

自己动手实现一个RPC框架
使用fastjson,netty,反射,动态代理,zookeeper实现一个RPC框架。
代码链接:https://github.com/liunaijie/self-rpc-framwork`
各模块说明:
-
rpc-commons通用设置模块,包括网络传输的数据格式,请求编号工具类,反射工具类等一些底层协议,工具相关的内容 -
rpc-register
服务注册模块,主要包括服务的注册与发现功能。这里使用zookeeper来进行实现。
在这里,服务端注册时,使用通用模块中的ServiceDescriptor,ResponseServiceDescription类来进行注册ResponseServiceDescription类是ServiceDescription的子类,添加了实现类,实例地址等属性。 消费者查找服务时,发送ServiceDescription得到ResponseServiceDescription,一个类可能有多个实现类,多个实例,在返回时进行随机返回。 对于同一个实现的不同版本实现,或多个服务实例这种情况随机返回没有问题。对于不同实现类,采用随机返回可能有些问题,但是在spring中对于多实现类也需要指定实现类,所以后面再考虑更改。
rpc-server
消费者的部分,这里使用配置类,将各种实现的部分在配置类中进行定义。
|
|
这这个配置中,定义了服务启动的端口,网络传输,注册中心,编解码的各种实现,当我们需要更换实现时只需要在这里修改即可。
rpc-client
消费者端,通过代理来进行调用。
与生产者端类型,首先定义配置类:
|
|