All
前言
之前了解过位运算符,左移<<等于乘以2,右移>>等于除以2。但是我在看jdk源码的时候发现了一个>>>三个符号的,不明白这是什么意思,就去搜了一下,发现还挺多的知识点的,就整理了一下。
首先我们知道,我们编写的程序最终都是在计算机底层进行的,计算机底层也仅支持0、1两种符号。所以当时网上有个键盘只有0、1两个键,那才是大佬用的键盘。扯远了。。。
先来复习一下java的基本类型都占多少字节,占多少位(1字节等于8位):
| 类型 | 字节数 | 位数 | 大小范围 |
|---|---|---|---|
| byte | 1 | 8 | -2^8^~2^8^-1 |
| short | 2 | 16 | -2^16^~2^16^-1 |
| int | 4 | 32 | -2^32^~2^32^-1 |
| long | 8 | 64 | -2^64^~2^64^-1 |
| float | 4 | ||
| double | 8 | ||
| char | 2 | 16 | 一个char类型可以存储一个汉字 |
| boolean | 1 | true or false |
移位操作是把数据看作二进制数,然后将其向左或向右移动若干位的运算。在Java中,移位操作符包含三种:<<左移运算符,>>带符号右移运算符,>>>无符号右移运算符。这三种操作符都只能作用于long,int,short,byte这四种基本整形类型上和char类型上。其他类型如double都无法使用位运算符,大家可以在ide中自行试验一下。
在java中,第一位用来表示数字的正负,第一位为零时表示正数,第一位为1时表示负数。我们拿最简单的8位byte类型举例:0000 0000表示0,0111 1111这个表示最大值(2^8^-1),再进行加一后就变成了1000 0000这时就变成了最小值(-2^8^)。再加一后变成1000 0001这时的值为-127。也就是从0到最大值然后转为最小值,然后再从最小值向零靠近。
基于《算法》一书的红黑树的插入和删除。看过不同的教材,也有不同的实现方式,但是最终的结果也大致相同,感觉这个比较容易理解,就采用这种的方式来进行简单实现。
定义树节点的实体类型
|
|
这里简单的定义了一下红黑树,并且只有节点,并不是map这样的k-v结构。如果定义k-v结构到时比较的时候比较k即可。
用了泛型,并且要支持比较(继承自Comparable),不然无法比较大小进行插入。
然后定义了一个值,左节点和右节点,然后颜色默认为红色。
再增加一个构造函数即可
今天继续来看一下Java中古老的集合类-Vector
变量
|
|
从上面的变量可以得知,Vector也是使用数组来进行底层的数据存储,并且还设置了扩容容量。
最近在看源码的时候看到一个关键字transient,之前对这个字没有印象,所以就去看了一下它的作用。
transient的作用
首先放上来着维基百科的解释:
Java 提供自动序列化,需要以
java.io.Serializable接口的实例来标明对象。实现接口将类别标明为“可序列化”,然后Java在内部处理序列化。在Serializable接口上并没有预先定义序列化的方法,但可序列化类别可任意定义某些特定名称和签署的方法,如果这些方法有定义了,可被调用运行序列化/反序列化部分过程。该语言允许开发人员以另一个Externalizable接口,更彻底地实现并覆盖序列化过程,这个接口包括了保存和恢复对象状态的两种特殊方法。在默认情况下有三个主要原因使对象无法被序列化。其一,在序列化状态下并不是所有的对象都能获取到有用的语义。例如,
Thread对象绑定到当前Java虚拟机的状态,对Thread对象状态的反序列化环境来说,没有意义。其二,对象的序列化状态构成其类别兼容性缔结(compatibility contract)的某一部分。在维护可序列化类别之间的兼容性时,需要额外的精力和考量。所以,使类别可序列化需要慎重的设计决策而非默认情况。其三,序列化允许访问类别的永久私有成员,包含敏感信息(例如,密码)的类别不应该是可序列化的,也不能外部化。上述三种情形,必须实现Serializable接口来访问Java内部的序列化机制。标准的编码方法将字段简单转换为字节流。原生类型以及永久和非静态的对象引用,会被编码到字节流之中。序列化对象引用的每个对象,若其中未标明为
transient的字段,也必须被序列化;如果整个过程中,引用到的任何永久对象不能序列化,则这个过程会失败。开发人员可将对象标记为暂时的,或针对对象重新定义的序列化,来影响序列化的处理过程,以截断引用图的某些部分而不序列化。Java并不使用构造函数来序列化对象。
从上面的最后一段可以了解,如果没有添加transient关键字,则会被进行序列化。也就是说添加了这个关键字后就不会被序列化。
接下来我们将用一个例子来测试一下
题目描述
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数
pos来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果pos是-1,则在该链表中没有环。示例 1:
输入:head = \[3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
示例 2:
输入:head = \[1,2], pos = 0 输出:true 解释:链表中有一个环,其尾部连接到第一个节点。
示例 3:
输入:head = \[1], pos = -1 输出:false 解释:链表中没有环。
进阶:
你能用 O(1)(即,常量)内存解决此问题吗?



Hashtable虽然现在不经常被用到,但是它作为Java最早的集合类,今天来看一下它的源码。
首先说明一个问题,在Java中大部分都是驼峰式写法,但是Hasbtable并没有采用这种写法。
继承与实现关系
|
|
可以看出它继承的是Dictionary与HashMap并不是同一个父类。但是它也实现了Map,Cloneable,Serializable接口。说明它可以被克隆,可以执行序列化。
变量
|
|
来一个一个的解释每一个变量的意义:
- table
与HashMap一样,利用数组作为底层的存储容器,并且添加了关键字transient。这个关键字的意思是在进行序列化的时候不会被序列化。这个关键字具体可以看一下这篇文章。
- count
表示容器中存储的数量
- threshold
扩容阈值,当容器中的数量到达这个值后会进行扩容机制。这个值默认情况下为 (capacity* loadFactor)
- loadFactor
扩容系数,默认为0.75f。
- modCount
修改次数,当增加或删除时,这个值会进行加一。表示这个容器结构修改的次数。这个变量在迭代,序列化等操作、多线程的操作下都尽量保证了安全性。
简单项目
首先我们建立一个项目,它作为我们的全部项目的容器,并负责公共依赖的版本管理等。
项目结构是这样的:
然后我们在pom.xml中导入我们所需要的依赖,我们全部使用 springboot 来启动项目,并且需要修改packaging的方式为pom。最终的文件如下所示:
|
|
题目来源
今天做了个题:
将一个链表里的数据组装树形结构,链表里的数据已经满足树形结构要求
这道题描述的很简单,但是有很多种情况。他只说了链表数据满足树形结构要求,并没有说明数据到底是什么样的,也就是题目参数具有多样性,这样其实我们给出一种解决方案就可以。而且也只要求将链表转换为树,并没有说是什么树。所以这道题说难也难,说简单也简单。
解题思路
最近也将平衡二叉树的原理看了一下,正好借着这道题将代码手写一下。
我写了一个平衡二叉树的插入方法。我们不管链表里面的数据是如何排序的,我们只要调用树的插入方法即可。在插入方法内部实现树的平衡。
所以我们这道题也就转换成了手写平衡二叉树的插入过程。
题目描述
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1:
给定 nums = [3,2,2,3], val = 3,
函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。
你不需要考虑数组中超出新长度后面的元素。 示例 2:
给定 nums = [0,1,2,2,3,0,4,2], val = 2,
函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
注意这五个元素可为任意顺序。
你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝 int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。 // 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。 for (int i = 0; i < len; i++) { print(nums[i]); }
二叉树
定义
- 二叉树由节点的有限集合构成
- 这个有限集合或者为空集
- 或者为由一个根节点(root)及两棵互不相交、分别称为这个根的左子树和右子树的二叉树组成的集合
在 java 中用代码定义为:
|
|
性质
- 在二叉树中,第 i 层上最多有2^i^ 个节点(i>=0)
- 深度为 k 的二叉树至多有2^k+1^-1个节点(k>=0)
- 有 n 个节点的完全二叉树的高度为 log
2(n+1)
它主要有五种基本形态:
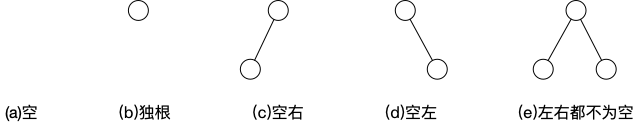
满二叉树
定义:除最后一层无任何子节点外,每一层上的所有节点都有两个子节点的二叉树。
大体的意思就是:一颗二叉树的节点要么是叶子节点(也就是最后一层),要么它就要有两个子节点。如果这个二叉树的层数为 k,且节点总数是(2^k^-1),则它就是满二叉树。
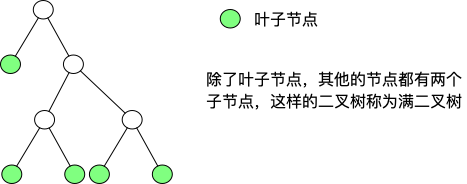
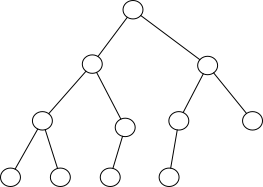
完全二叉树
定义:设二叉树的深度为 k,除第 k 层外,其他各层(1~(k-1)层)的节点都都达到最大值,其第 k 层所有的节点都连续集中在最左边,这样的树就是完全二叉树
这些是二叉树的一些基本定义以及变形,它对于数据的存储并没有要求,只是要求了结构。所以对于实际应用中还存在很多的不足,比如对于一个 n 个节点的树,判断一个节点是不是在树里面,它的复杂度还是 o(n)。所以我们下面介绍几种对于存储有要求的树。