All
垃圾收集器
垃圾收集需要完成三件事情:
- 哪些地方的内存需要回收?
- 如何判断能否回收?
- 如何回收?
Java OOM异常分析
OOM异常分析
Java堆溢出
Java堆内存的OutOfMemoryError异常是实际应用中最常见的内存溢出异常情况. 出现Java堆内存溢出时, 异常堆栈信息“java.lang.OutOfMemoryError”会跟随进一步提示“Java heap space“
可能的原因有:
-
内存泄漏
-
内存溢出
需要从代码上检查是否存在某些对象生命周期过长、持有状态时间过长、存储结构设计不合理的情况, 尽量减少程序运行期的内存消耗
要处理这个内存区域的异常, 常规的处理方法是通过内存映像分析工具对Dump出来的堆转储快照进行分析.
Java对象创建
当Java虚拟机遇到一条字节码new指令时, 首先将去检查这个指令的参数能否在常量池中定位到一个类的符号引用, 并且检查这个符号引用代表的类是否被加载, 解析和初始化. 如果没有则会先执行相应的类加载过程.
对象的创建过程大致分为以下四步:
- 为新生对象分配内存
- 虚拟机将分配到的内存空间(不包括对象头)都初始化为零值
- 对对象进行必要的设置, 例如这个对象是哪个类的实例, 如果找到这个类的元数据信息, 对象的GC分代年龄等, 这些信息存放在对象的对象头之上
- 执行Class文件额init方法
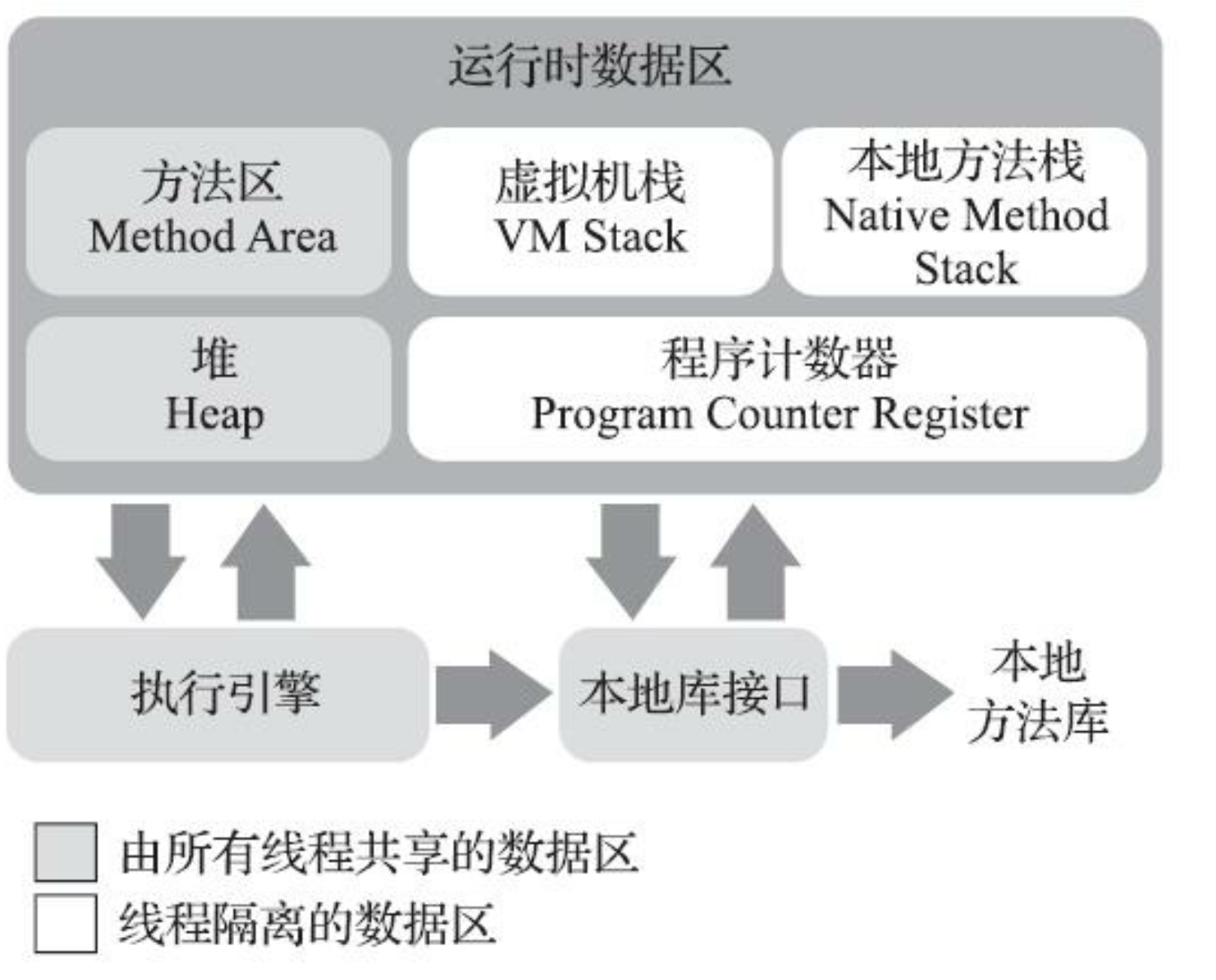
JVM运行时数据区域
Java虚拟机所管理的内存包括以下几个运行时数据区域:
这篇文章记录下使用Git时的一些进阶操作, 命令.
前言
这篇文章记录一下ClickHouse的几种原生引擎的数据写入过程
MergeTree
MergeTree是ClickHouse的最基础引擎,其它引擎都是基于这个引擎来进行扩展的,所以先来看一下这个引擎的写入过程。
先看一下要创建这个引擎的DDL语句:
|
|
题目描述
将IPV4的地址转换成int值,然后再将其转换回来
kylin是什么
在进行数据分析时,随着数据量的提升,处理时间基本也是线性增长。kylin是一个预处理框架,它将一些预先定义的复杂分析预先完成并进行存储,预处理完成后,再次进行请求时,kylin可以进行亚秒级别的响应。
它是一个分析型数据仓库(也是OLAP引擎),为Hadoop提供标准SQL支持大部分查询功能
可以接入kafka等实时流处理数据,从而可以在妙极延迟下进行实时数据等多维分析。
处理引擎可以选用MapReduce和Spark。
于BI工具无缝整合,可以接入Tableau,PowerBI/Excel,SuperSet等可视化分析工具。
我总结出来的观点呢就是:当我们的数据量非常大之后,每次查询都需要花费很多时间,这时我们将查询结果缓存起来,后面查询从这个缓存里面查询速度就会非常快。在kylin中,将结果缓存到hbase表中。
这里需要预先设置一些维度和度量,所以说适合一些固定报表等一些维度固定的场景,如果说维度的组合太多或者变化很频繁,可能不是很适用。