Tag - "Java"
2022
2020
fail-fast与fail-safe
在Collection集合的各个类中,有线程安全和线程不安全这2大类的版本。
对于线程不安全的类,并发情况下可能会出现fail-fast情况;而线程安全的类,可能出现fail-safe的情况。
**快速失败(fail—fast)**是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
**安全失败(fail-safe)**保存了该集合对象的一个快照副本。你可以并发读取,不会抛出异常,但是不保证你遍历读取的值和当前集合对象的状态是一致的!
fail-fast
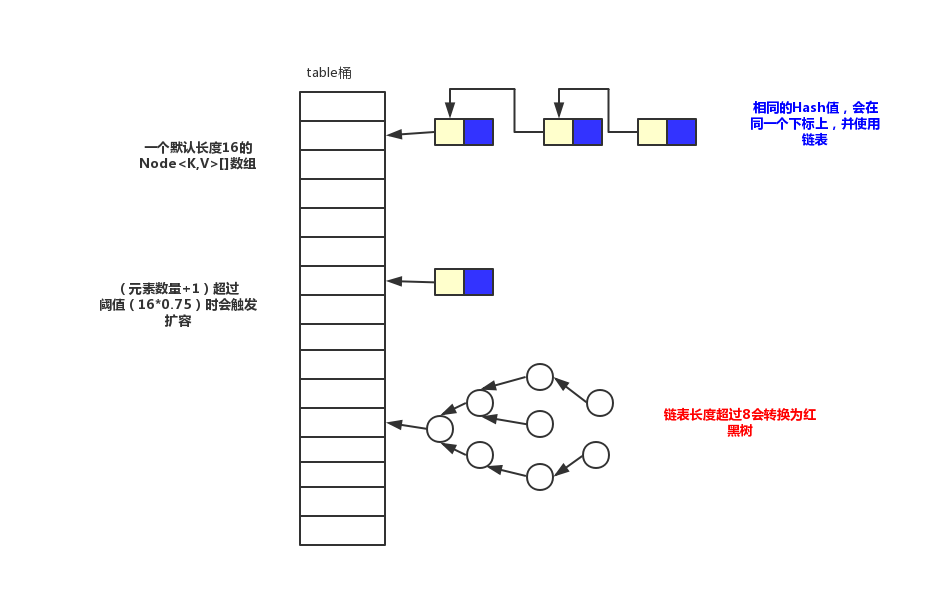
来看一下线程不安全的类ArrayList,它实现fail-fast主要靠一个字段modCount。来从头认识一下它。
首先找到引用它的地方:
|
|
可以看出,在增加元素,删除元素时都会对modCount值加一。当我们查看更新,查找的代码时并没有找到对modCount的修改。
modCount字段翻译过来就是修改次数,再结合上面的代码可以了解到只有在结构发生变化,数量增减的时候才会修改。查找不会对结构发生变化也不用修改,至于更新操作,虽然它修改了值,但是在结构上总体的数量没有改变,结构上指的是:是谁不重要,有就行。
2019
前言
之前了解过位运算符,左移<<等于乘以2,右移>>等于除以2。但是我在看jdk源码的时候发现了一个>>>三个符号的,不明白这是什么意思,就去搜了一下,发现还挺多的知识点的,就整理了一下。
首先我们知道,我们编写的程序最终都是在计算机底层进行的,计算机底层也仅支持0、1两种符号。所以当时网上有个键盘只有0、1两个键,那才是大佬用的键盘。扯远了。。。
先来复习一下java的基本类型都占多少字节,占多少位(1字节等于8位):
| 类型 | 字节数 | 位数 | 大小范围 |
|---|---|---|---|
| byte | 1 | 8 | -2^8^~2^8^-1 |
| short | 2 | 16 | -2^16^~2^16^-1 |
| int | 4 | 32 | -2^32^~2^32^-1 |
| long | 8 | 64 | -2^64^~2^64^-1 |
| float | 4 | ||
| double | 8 | ||
| char | 2 | 16 | 一个char类型可以存储一个汉字 |
| boolean | 1 | true or false |
移位操作是把数据看作二进制数,然后将其向左或向右移动若干位的运算。在Java中,移位操作符包含三种:<<左移运算符,>>带符号右移运算符,>>>无符号右移运算符。这三种操作符都只能作用于long,int,short,byte这四种基本整形类型上和char类型上。其他类型如double都无法使用位运算符,大家可以在ide中自行试验一下。
在java中,第一位用来表示数字的正负,第一位为零时表示正数,第一位为1时表示负数。我们拿最简单的8位byte类型举例:0000 0000表示0,0111 1111这个表示最大值(2^8^-1),再进行加一后就变成了1000 0000这时就变成了最小值(-2^8^)。再加一后变成1000 0001这时的值为-127。也就是从0到最大值然后转为最小值,然后再从最小值向零靠近。
今天继续来看一下Java中古老的集合类-Vector
变量
|
|
从上面的变量可以得知,Vector也是使用数组来进行底层的数据存储,并且还设置了扩容容量。
最近在看源码的时候看到一个关键字transient,之前对这个字没有印象,所以就去看了一下它的作用。
transient的作用
首先放上来着维基百科的解释:
Java 提供自动序列化,需要以
java.io.Serializable接口的实例来标明对象。实现接口将类别标明为“可序列化”,然后Java在内部处理序列化。在Serializable接口上并没有预先定义序列化的方法,但可序列化类别可任意定义某些特定名称和签署的方法,如果这些方法有定义了,可被调用运行序列化/反序列化部分过程。该语言允许开发人员以另一个Externalizable接口,更彻底地实现并覆盖序列化过程,这个接口包括了保存和恢复对象状态的两种特殊方法。在默认情况下有三个主要原因使对象无法被序列化。其一,在序列化状态下并不是所有的对象都能获取到有用的语义。例如,
Thread对象绑定到当前Java虚拟机的状态,对Thread对象状态的反序列化环境来说,没有意义。其二,对象的序列化状态构成其类别兼容性缔结(compatibility contract)的某一部分。在维护可序列化类别之间的兼容性时,需要额外的精力和考量。所以,使类别可序列化需要慎重的设计决策而非默认情况。其三,序列化允许访问类别的永久私有成员,包含敏感信息(例如,密码)的类别不应该是可序列化的,也不能外部化。上述三种情形,必须实现Serializable接口来访问Java内部的序列化机制。标准的编码方法将字段简单转换为字节流。原生类型以及永久和非静态的对象引用,会被编码到字节流之中。序列化对象引用的每个对象,若其中未标明为
transient的字段,也必须被序列化;如果整个过程中,引用到的任何永久对象不能序列化,则这个过程会失败。开发人员可将对象标记为暂时的,或针对对象重新定义的序列化,来影响序列化的处理过程,以截断引用图的某些部分而不序列化。Java并不使用构造函数来序列化对象。
从上面的最后一段可以了解,如果没有添加transient关键字,则会被进行序列化。也就是说添加了这个关键字后就不会被序列化。
接下来我们将用一个例子来测试一下
Hashtable虽然现在不经常被用到,但是它作为Java最早的集合类,今天来看一下它的源码。
首先说明一个问题,在Java中大部分都是驼峰式写法,但是Hasbtable并没有采用这种写法。
继承与实现关系
|
|
可以看出它继承的是Dictionary与HashMap并不是同一个父类。但是它也实现了Map,Cloneable,Serializable接口。说明它可以被克隆,可以执行序列化。
变量
|
|
来一个一个的解释每一个变量的意义:
- table
与HashMap一样,利用数组作为底层的存储容器,并且添加了关键字transient。这个关键字的意思是在进行序列化的时候不会被序列化。这个关键字具体可以看一下这篇文章。
- count
表示容器中存储的数量
- threshold
扩容阈值,当容器中的数量到达这个值后会进行扩容机制。这个值默认情况下为 (capacity* loadFactor)
- loadFactor
扩容系数,默认为0.75f。
- modCount
修改次数,当增加或删除时,这个值会进行加一。表示这个容器结构修改的次数。这个变量在迭代,序列化等操作、多线程的操作下都尽量保证了安全性。
注解,这个经常在开发中使用到的东西,它的使用语法是怎么样的?如何去自定义一个注解呢?
什么是注解
我们在日常开发中,比如 java 中的@Override,在 springboot 中用到的@SpringBootApplication等一系列标注在类或者方法上的注解。我们添加上注解后会有对应的事件处理,比如我们的@Override注解标明这个方法是重写了父类或者接口的方法,当参数不一致、返回类型不一致等不符合重写的要求时,编译器会报错。类似的@SpringBootApplication也是标明这个项目的一个 springboot 项目,默认会启动一个 tomcat 容器等。
注解是从 jdk5 开始引入的新特性。
注解的语法
|
|
通过@interface即可声明一个注解。
在脉脉上看到一篇文章,StringBulider 为什么线程不安全,然后想了一下,确实不知道。
之前问string 相关问题,只了解了 string 不可变,stringbuffer 线程安全,stringbuilder 线程不安全。但却没有搞清楚为什么是不安全的,今天就去看了一下 stringbuilder 的源码,来了解一下原因。
首先来测试一下多线程下的不安全问题:
|
|
这个方法最终的理想结果应该是 100000,但是当我们多运行几次,发现他的结果出错了!结果变成了99999或者更小的数值。有时候甚至还抛出了数组越界异常(概率极小)。
之前看过了HashMap,LinkedHashMap的源码,这次来看一下TreeMap的源码。
从这个名字就能看出,TreeMap底层使用的是树来进行存储的。
变量
|
|
看一下 root 节点的数据结构:
|
|
由于有一个color=BLACK属性,所以底层数据结构应该是红黑树
基础概念
线程的所有状态:
这些状态都在 Thread中的State枚举中定义:
|
|
初始线程
-
Thread类 -
Runable接口Thread类中调用start()方法之后会让线程执行run()方法,而run()方法中又是对Runable实例的调用1 2 3 4 5 6 7 8 9/* What will be run. */ private Runnable target; @Override public void run() { if (target != null) { target.run(); } }
JAVA基础
类的初始化顺序
静态变量和静态语句块会优先于实例变量和普通语句块
|
|
- 父类(静态变量,静态语句块)
- 子类(静态变量,静态语句块)
- 父类(实例变量,普通语句块)
- 父类(构造函数)
- 子类(实例变量,普通语句块)
- 子类(构造函数)
迭代器
在java中主要有两种迭代器,Iterator和ListIterator。这两个都是接口。先来看一下这两个接口有什么区别
|
|
Iterator主要有四个方法。判断有没有下一个元素、获取下一个元素,删除元素和forEachRemaining方法。
再来看一下ListIterator
|
|
我们可以看到他是继承了Iterator。除了上面的两个方法还多了好几个方法。判断是否有上一个元素,获取上一个元素的值,获取上一个元素的索引,获取上一个元素的索引。除了移除还有添加和更新的方法。
他们在不同的类里面都有自己的实现,之前看ArrayList,HashMap的时候把这一块给跳过了,现在来看一下他们是如何实现的。
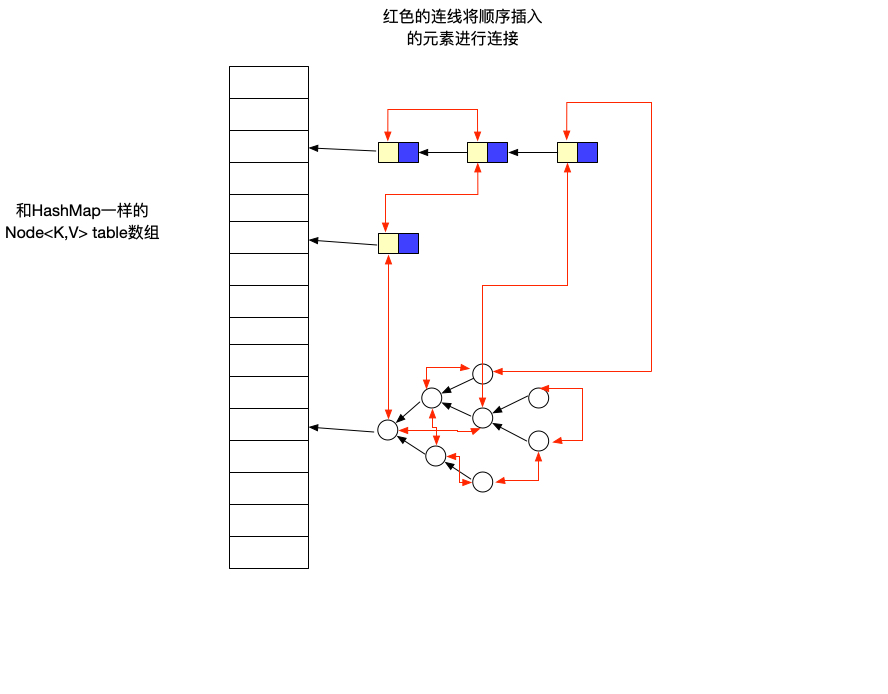
LinkedHashMap继承了HashMap类,实现了Map接口。
他与HashMap的主要区别就是使用链表存储了每个节点的顺序。这样就能保证有序。
来看一下他的节点情况:
|
|
从这里可以看出他使用了两个变量,before,after存储这个节点的前后顺序。
画了一张结构图,欢迎指正。
变量
|
|
LinkedList使用了链表实现,相比ArrayList来说,插入更快,查看较慢。
首先看一下使用的链表结构
|
|
每个Node节点存储一个元素,item表示这个元素的值,prev表示上一个元素,如果已经的第一个了那么为null。同理,next表示的是下一个元素,当插入新元素时会改变上一个元素的next值指向自己,这样就把这个链表串起来了。
变量
|
|
变量
|
|
DEFAULT_CAPACITY:默认的容量,当我们不指定容量时默认容量是10EMPTY_ELEMENTDATA:空的数据集DEFAULTCAPACITY_EMPTY_ELEMENTDATA:同上面的一样,都是空的数据集elementData:保存的元素size:元素长度,实际存储的元素数量
构造方法:
- 无参的构造方法
|
|
很简单的一句话,将保存元素的变量进行初始化。